Global PyPI Scan¶
The Aura team conducts periodic scans of the PyPI repository on a best effort basis where we scan the latest version of all published packages. The diagram below depicts an overview of the architecture being used to conduct these scans:
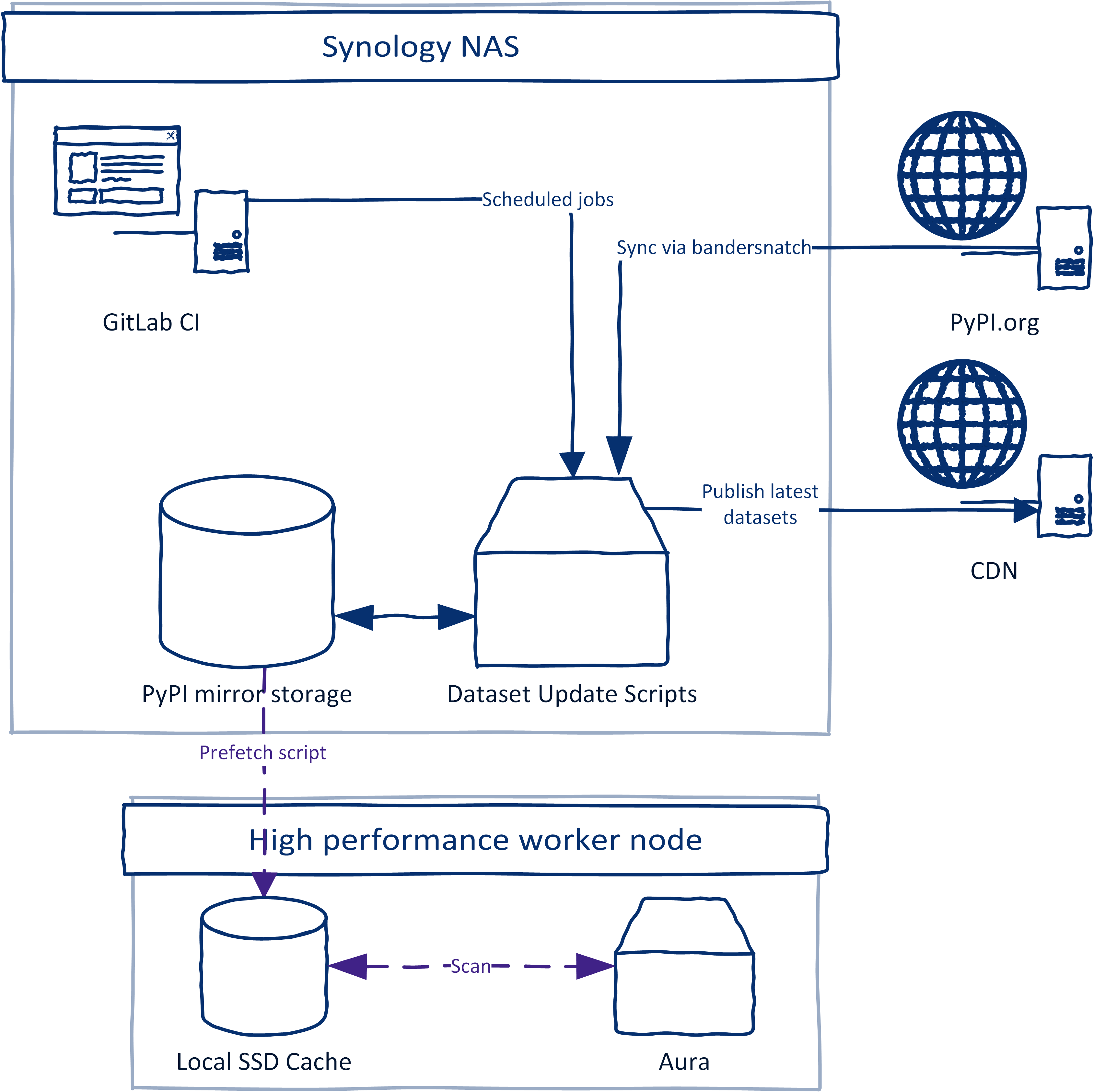
The central piece of this is a Synology server which hosts an offline copy of the PyPI repository. This offline repository is being synced periodically every hour with the official PyPI repository using bandersnatch via custom dataset update scripts. The synchronization is invoked using scheduled Gitlab CI pipelines on a runner hosted on the server. After the PyPI synchronization is finished, new Datasets are being re-generated where applicable and uploaded to our CDN for public access.
The PyPI scan itself is done on a separate high-performance worker node. While it is possible to scan the offline PyPI repository directly we opted for a few changes to increase the performance and avoid problems such as network outages. We observed that the network latency and time to transfer the PyPI packages from NAS to the worker node were severely impacting the performance and total run time of the scan.
The worker node has a fast SSD disk dedicated to caching the packages for the scan that are prefetched from the offline PyPI mirror right before the scan starts. After the prefetch is completed a full scan of all packages is conducted by running parallel Aura scans. All scripts used on the worker node are available under the files/ directory at the root of the Aura repository.
The full list of published PyPI datasets is available at: https://cdn.sourcecode.ai/pypi_datasets/index/datasets.html
Technical specification of the worker node:
CPU |
AMD Ryzen 9 3900X 12-Core Processor |
RAM |
HyperX 32GB Kit DDR4 3200MHz CL16 XMP |
GPU |
SAPPHIRE NITRO+ Radeon RX 580 OC 8G |
Disk |
2x Intel 660p M.2 2TB SSD NVMe |
OS |
Arch Linux (fully updated prior to scan) |
Description of the dataset¶
Data produced from global scans are distributed via magnet (torrent) links with metadata hosted on SourceCode.AI CDN. The dataset content is as follows:
dataset.zst - Single file dataset compressed using ZSTD. Each line contains a compact JSON per scanned PyPI package
joblog.txt - Joblog file from GNU Parallels
input_packages.txt - List of PyPI packages passed as input for the global PyPI scan
package_list.txt - List of PyPI packages actually processed by Aura during the scan, each package listed in this file has an entry in a dataset.zst file
checksums.md5.txt - List of MD5 checksums for all files contained within the dataset
README.txt - License & copy of this description
You may have noted that there is a difference between the file input_packages.txt and package_list.txt. The input file is generally larger and is of all packages contained in our offline PyPI mirror at the start of a global scan. However, some packages may have not any releases published and so they would be skipped by Aura during the actual scan. Other reasons may include that the package has a corrupted archive, timeout for a scan has been reached or Aura crashed during the scan of a package. This is the reason why the input package list is always larger than the actual list produced by Aura during/after the scan.
To quickly process or glance at the data, we highly recommend to use the jq data processor . Description of the dataset format can be found in the following documentation Built-in detections.
The dataset is released under the CC BY-NC 4.0 license . Use the following citation to give attribution to the original research paper:
@misc{Carnogursky2019thesis,
AUTHOR = "CARNOGURSKY, Martin",
TITLE = "Attacks on package managers [online]",
YEAR = "2019 [cit. 2020-11-02]",
TYPE = "Bachelor Thesis",
SCHOOL = "Masaryk University, Faculty of Informatics, Brno",
SUPERVISOR = "Vit Bukac",
URL = "Available at WWW <https://is.muni.cz/th/y41ft/>",
}
